Migrating a Legacy App to Cloud Native — Part 6

I'm a Consulting Software Engineer, Software Architect, and AWS Solutions Architect with over 34 years of experience. My specializations include AWS serverless application development, IoT, and webapps.
I performed too well growing with the Cloud Native application development practice of a Premier AWS Consulting Partner, and got myself promoted to management. 😔
Now I'm returning to my true self as a full spectrum software engineer and cloud technologist; from discovery to delivery and everything between.
This is part 6 in a series documenting my journey. If you haven’t been following it before now, here are the previous posts:
- Part 1: Background
- Part 2: Requirements & Architecture
- Part 3: Authentication
- Part 4: Add Cloud Storage
- Part 5: Use Cloud Storage
Review Our Goal
User settings and collections can be saved to and retrieved from the cloud. Now I need to finish off publishing “public” collections and add in the ability for other users to find these. Let’s refer back to the architecture diagram:
In this series installment, I will implement the row down the middle: AppSync, DynamoDB, and the Validate & Index lambda.
The last time I showed this diagram, the two lambdas were outside of the “Managed by AWS Amplify” box. I have since found how to include those within Amplify…
Amplify API is AppSync
Amplify has two options for implementing APIs. One is a traditional API Gateway to Lambda approach, that Amplify refers to as REST. (Nothing about it actually enforces RESTfulness, it simply can be RESTful.) Beyond the Amplify documentation, I have seen no chatter about this option. When someone talks about Amplify API, they’re talking GraphQL. On the AWS cloud end, this is done using the AppSync service.
I’ll add an API to SqAC via the amplify add api command:
$ amplify add api
? Please select from one of the below mentioned services GraphQL
? Provide API name: sqacamplify
? Choose an authorization type for the API Amazon Cognito User Pool
Use a Cognito user pool configured as a part of this project
? Do you have an annotated GraphQL schema? No
? Do you want a guided schema creation? Yes
? What best describes your project: Single object with fields (e.g., “Todo” with ID, name, description)
? Do you want to edit the schema now? Yes
Please edit the file in your editor: /Users/adamfanello/dev/sqac/sqac-amplify/amplify/backend/api/sqacamplify/schema.graphql
? Press enter to continueGraphQL schema compiled successfully.
For authorization I chose Amazon Cognito User Pool, which is what you want for user-facing clients. I’m actually building a public read-only API and thus won’t enforce any authentication, but there’s no “none” option.
My GraphQL API schema is extremely simple. Really, I could easily do this by other means with a single DynamoDB table and the REST API option — or even with the client accessing DynamoDB directly! The point of this journey is to try new things though, thus GraphQL and AppSync with Amplify. Here’s the GraphQL schema:
type Collection
# Store in DynamoDB, disable mutations and subscriptions
@model( mutations: null, subscriptions: null)
{
id: ID!
created: String!
modified: String!
revision: Int!
name: String!
author: String!
authorUserId: String!
description: String!
difficulty: Int!
level: String!
formations: Int
families: Int
calls: Int
modules: Int!
license: String!
}
This is a public read-only API, thus in the model I’m disabling all mutations and there’s no @auth directive. This simply lets users of the app search for collections that the individual authors have released to the public. The @model directive tells Amplify to expand this type with a GetCollection query and a ListCollections query, and all the GraphQL input and output types needed to drive those. (It would have done more had I not disabled mutations and subscriptions.) Best of all, since Amplify knows I’m using the Angular framework, it also generated Typescript types and an Angular service for me to use. The result: I don’t actually have to touch GraphQL in my client; it’s simply a function call to do what I need. 😎
The DynamoDB table created is by default PAY_PER_REQUEST, which makes it truly serverless. However, this on-demand option does not fall under the AWS free tier. So I switched DynamoDBBillingMode to PROVISIONED with the default of 5 RCU and 5 WCU - which fits within free tier and is plenty for my app’s current needs.
S3 Trigger Lambda
Since the API is read-only, you may wonder where the data comes from. That’s the job of the Validate & Index lambda — an S3 trigger. Whenever a collection is uploaded, it’ll trigger this Lambda that will manage public collections, including updating the DynamoDB table that this API is reading from. Adding the trigger:
$ amplify update storage
? Please select from one of the below mentioned services Content (Images, audio, video, etc.)
? Who should have access: Auth and guest users
? What kind of access do you want for Authenticated users? (Press to select, to toggle all, to invert selection)create/update, read, dele
te
? What kind of access do you want for Guest users? (Press to select, to toggle all, to invert selection)read
? Do you want to add a Lambda Trigger for your S3 Bucket? Yes
? Select from the following options Create a new function
Successfully added resource S3Trigger08755fbf locally
? Do you want to edit the local S3Trigger08755fbf lambda function now? Yes
Please edit the file in your editor: /Users/adamfanello/dev/sqac/sqac-amplify/amplify/backend/function/S3Trigger08755fbf/src/index.js
? Press enter to continue
Successfully updated resource
This wiped out all my customization in storage/parameters.json as described in part 5. 😑 Fortunately, I have the good sense to review all the changes from a CLI tool before committing them, and so was able to revert the damage leaving only the “triggerFunction” parameter changed.
I also edited the CloudFormation template for this function to use Node.js 10 and limit to a single concurrent execution. (Amplify is still setting Lambdas to the Node.js 8 runtime, even though its deprecation is only five weeks from when I write this.)
Now I need this trigger to be able to write to the Collection table in DynamoDB. For this, two things are needed:
- The lambda needs the name of the table.
- The lambda needs permission to write to the table.
Finding the table
This required some experimentation and mild hackery. Amplify doesn’t provide any information other than the environment name (“dev”) to the trigger Lambda. Looking in AWS Console, I see that the table name is a concatenation of my type name “Collection”, the generated AppSync API identifier, and the environment name. “Collection” is a static name and so safe to hard code. The environment is provided to the Lambda via environment variable (overloading the word “environment” in different contexts), and the AppSync ID I found in the amplify-meta.json file. 🤔 I tried doing a Javascript require(‘../../../amplify-meta’) to fetch this content, but the file wasn’t delivered as part of the Lambda source and thus failed at runtime. (I expected as much, but it was worth a try.) With some searching, I found that Amplify has a pre-deployment hook capability, as described in the documentation. 🎉 I used this package.json script to copy amplify-meta.json to the function src directory, and added Typescript compilation while at it!
In the Lambda’s package.json at amplify/backend/function/S3Trigger08755fbf/src/
"scripts": {
"build": "cp ../../../amplify-meta.json . && ../../../../../node\_modules/.bin/tsc"
}
In the Lambda src directory, I also ran tsc --init to generate a tsconfig.json and thus ready for Typescript.
Then in my top-level package.json:
"scripts": {
"amplify:S3Trigger08755fbf": "cd amplify/backend/function/S3Trigger08755fbf/src/ && npm run build"
}
It could have all been put in the top-level, but this way I can do trial builds from the lambda src directory. Now whenever doing an amplify push, the latest meta data will be copied and Typescript compiled. 🎉
(Of course I added the copied amplify-meta.json and compiled .js output to my .gitignore file.)
Put all together, my Lambda source code now includes:
const amplifyMeta = require('./amplify-meta');
const ddbTableName = 'Collection-'
+ amplifyMeta.api.sqacamplify.output.GraphQLAPIIdOutput
+ '-' + process.env.ENV;
I did attempt another approach as mentioned here, where @mikeparisstuff states that if I just define an input parameter for a CloudFormation stack (say, the S3 trigger lambda), then Amplify will provide the value. I tried this with AppSyncApiId, but it failed as unresolvable. Perhaps this works only within the API category.
Adding permissions
There may be elegant solutions for adding permission for the S3 trigger lambda to access the DynamoDB table, but I couldn’t find any. I simply added the new statement to the policy given to the lambda’s execution role, right in the storage category’s CloudFormation. I even gave it access to all resources, which I feel is fine because I’m following the practice of one environment to one AWS account. As such the wildcard resource only gives access to the one DynamoDB table in the account. Specifically, I modified the S3TriggerBucketPolicy in amplify/backend/storage/storage/s3-cloudformation-template.json to add this to the Statement array:
{
"Effect": "Allow",
"Action": [
"dynamodb:PutItem",
"dynamodb:DeleteItem",
"dynamodb:GetItem",
"dynamodb:Query",
"dynamodb:UpdateItem"
],
"Resource": "\*"
}
The S3 Trigger Logic
Amplify created a bare bones example Lambda, and I have now given it permission to access the DynamoDB table created by the Amplify API category. Now I have to write up the exact logic. 🙌 This is the easy part for me. Infrastructure is meh 🤷♂. Fighting with tools is argh! 😱 Getting back to just writing some code with familiar tools, language, and services is like comfort food; I can just relax and enjoy. 🤗
After some iterative experimentation and coding, the Lambda was written. You can find it in PR #7. (Notice the actual handler is just eight lines of loop and error handling — everything else is in small helper functions. Access to S3 and DynamoDB are abstracted into the storage.ts and database.ts files.)
The resulting logical flow is described below. Note that there is only one S3 bucket and one Lambda (with multiple executions). They are shown repeatedly here to break it down by steps.
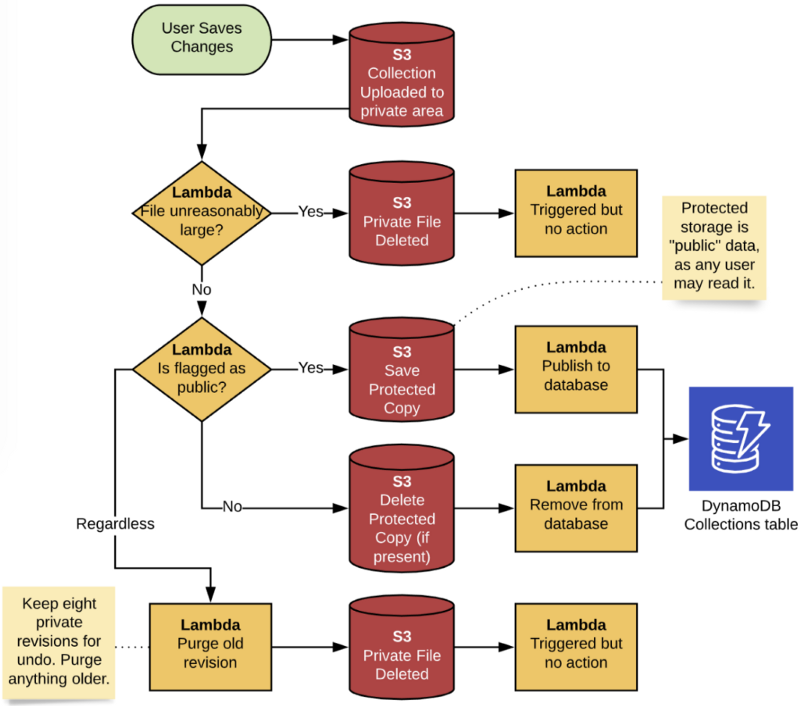
The “Triggered but no action” lambda executions are unfortunate side effects because everything is in one bucket and without pre-execution filtering. (Hand-rolled S3 allows both of these approaches, but not Amplify.) Since the Lambda will always be warm at those two points (I set concurrency to one), it’s just a quick sub-100 millisecond execution to detect state and exit.
Implement Search in Client
To start using the Amplify API category, the first step is to add API to the list of Amplify modules registered in app.module.ts, as described here. The exact code to add for this is not specified; the linked documentation just has examples for three other categories. The key is import API from "@aws-amplify/api"; and then add API to the object passed to AmplifyModules.
My search capability allows the user to enter a bit of text, and then searches for that text in the collection’s name, description, and author’s name. The challenge was figuring out just how to do that with the generated ListComponents function. The input type allows for criteria to be given for each property, but does not specify whether multiple criteria is an and operation or an or operation. Experimentation found that it’s anAND, but what I really wanted was a mix of ORs (text in any of three properties) and ANDs for the other search criteria (difficulty and level properties). I finally noticed that the generated ModelCollectionFilterInput has three extra properties at the end that are not part of my data model: and, or, and not. That could work. By the time I noticed these I had also realized through my experimentation that the text searches are case-sensitive. This is how DynamoDB behaves, and thus so does AppSync talking to DynamoDB. In the end I added a searchText property to the GraphQL schema and added a bit to the Lambda to set this value when writing to DynamoDB. With this new property containing the three text fields concatenated and in all lower case, the input to ListComponents in the client can now simply set the relevant criteria using the lower-cased search text and default and operation behavior.
I explain all that dry detail because you won’t find it explained anywhere else. Even digging into the resolver for ListComponents lead to a dead end - a Velocity Template utility function that translates the input to a DynamoDB filter expression, but without the details of how. (Find toDynamoDBFilterExpression on this page if you want to see it.) Are you tired of me complaining about poor documentation? Me too. Moving on.
Here’s the good news: after this, the Amplify → Angular → GraphQL → AppSync → DynamoDB integration just worked! Once some details are cleared up, it’s really easy. 🎉 I linked to all the pertinent little bits of code in the paragraphs above.
Coming next time…
Upon completing this section, I was excited to realize that this migrated version of SqAC has reached feature parity with the existing production version! 🎉 🥳
There is one more feature on my to do list: guest accounts. Additionally, there are finishing touches such as S3 policy, revision purging by age, CloudWatch monitoring, and email notifications.
Until next time. 🙇♂️
(Story originally published here in November 2019.)




