Migrating a Legacy App to Cloud Native — Part 2

I'm a Consulting Software Engineer, Software Architect, and AWS Solutions Architect with over 34 years of experience. My specializations include AWS serverless application development, IoT, and webapps.
I performed too well growing with the Cloud Native application development practice of a Premier AWS Consulting Partner, and got myself promoted to management. 😔
Now I'm returning to my true self as a full spectrum software engineer and cloud technologist; from discovery to delivery and everything between.
Photo by Kaleidico on Unsplash
Last time (in part 1), I gave some background on the application to migrate (Square Auto-Choreographer; SqAC), and why I’m migrating it (to add IaC and learn the latest in cloud native development). Specifically, I gave the spoiler that I’m going to attempt this migration by using AWS Amplify. Review complete. 😛
Now on to part 2: Requirements & Architecture
What is AWS Amplify?
The blogosphere (real word) is full of articles about AWS Amplify. There’s a good chance you found your way here specifically on that keyword. Simply: Amplify is a full-stack serverless framework and CLI tool. It lets a developer focus on their (web, iOS, or Android) application, and use cloud services from AWS to provide things like user accounts and data persistence. At least that’s how it started. When I first looked at Amplify in 2018, it struck me as a toy for lone front-end developers to use AWS in very simple use cases. However, I also saw a very responsive development team at AWS and a lot of room for growth. And grow it has! A year later Amplify can now handle multiple environments, multiple developers, and overriding capabilities to leverage the full power of AWS for complicated use cases. The result now appears to be the best of both worlds: easy to get started with, simple to use, and the power to do anything! The “simple” cases have expanded to include analytics, chat bots, machine learning, publish/subscribe, push notifications, and virtual reality! This little framework/CLI tool combo has grown up to be a bit overwhelming!
For all my study, I haven’t built anything meaningful with it yet. That’s what this project is about.
Requirements
Step one though, is to figure out just which of these many features my applications needs. The front-end application with the business logic already exists and isn’t changing, so I’m not going to cover anything about dance choreography. 😉 What we’re concerned about here is, how do I swap out my hosted virtual machine outlined in part 1 with serverless capabilities provided by AWS Amplify. Thus the focus is there.
Business Requirements & Discussion:
Each application user (a dance caller) has their settings; consisting mainly of a list of others’ collections of choreography to use and sessions. Sessions store options used when calling to different groups of dancers. This information is private to the individual user and stored in the cloud so it can be accessed from any modern browser in any device.
- Amplify Authentication fits the bill for identifying users and keeping their data private. The current app only uses social login via Google and Facebook. I’ll try and keep these while adding Cognito user pools as well since some users are nervous about social login.
- The current app stores the settings as a simple JSON file. This data is accessed all at once and cached in the client. Amplify Storage fits this need, but should it target S3 or NoSQL (DynamoDB)?
Guest users can access public content, but cannot store any data in the cloud.
- The existing app requires login before the user can play with it; a barrier to entrance.
- Amplify Authentication has the concept of guest users, which can access public data but not save private content without an account.
Each collection can be many hundreds of kilobytes in size. (JSON format)
- Like user settings, collections are accessed at once and cached in the client.
- DynamoDB records are limited to 400 KB, so it cannot hold large collections.
- Thus collections will use Amplify Storage backed by S3.
- It looks like Amplify only allows S3 or DynamoDB for storage, not both. Thus user settings will also go into S3.
Users may revert to older revisions of collections, in case a mistake is made.
- Name each collection file with a revision number.
- Each update will actually create a new file in S3, never replacing existing files.
- A scheduled execution in AWS will need to delete older revisions based on count and age.
Collections can be private to the user, or publicly shared for other users to see.
- Combining Amplify Authentication with Amplify Storage provides a protected access class.
- Data that is protected is readable by everyone (thus public), but only writable by the user who created it.
Users can find and subscribe to other users’ public collections by searching for the collection by some meta-data (name, description, & others).
- Whenever a collection is saved to an S3 protected area, an s3:ObjectCreated event will trigger a Lambda. This lambda will load the content and update a parallel record in DynamoDB.
- Whenever a collection is removed from an S3 protected area, an S3:ObjectRemoved event will trigger a Lambda. This lambda will remove the parallel record in DynamoDB if it was the latest revision.
- Only the latest revision is searchable.
- The Amplify API with GraphQL feature will provide the search capability against the DynamoDB table.
- This could easily be done with the REST API feature instead, but then this way Amplify will manage the DynamoDB table, IAM, and I get to play with AppSync. 😌
The web app is a Progressive Web App (PWA) that works offline and on mobile networks. It needs to be able to find when collections and user settings have changed and download changes.
For the user’s own private and protected storage, the Storage.list API (directory listing) can be used to check for new content with minimal bandwidth use.
For subscriptions to others’ collections, a GraphQL query may be used to check for new revisions. Only if a newer revision is found is the file downloaded from Amplify Storage (S3).
On-going cost should be kept to a minimum, both by design and to manage risk.
- S3 storage is only free (5 GB) for 12 months, but is very cheap to store and read even after that.
- DynamoDB is free up to 25 GB of storage, with 25 read and write capacity units. Amplify uses on-demand pricing by default, which has no free tier. This can be changed to use provisioned access though, taking advantage of those free units.
- Avoid the @searchable directive in GraphQL, as this launches a costly not-serverless ElasticSearch instance. An occasional scan of DynamoDB for search will fall into the free tier, if the data is small.
- Set S3 policy to limit the size of each file. Two MB per file will be plenty for legitimate users, while deterring hackers from using my account for free storage.
- Set S3 policy to limit each user to 25 MB. Again, enough for legitimate use while deterring hackers.
- Monitor storage usage and alert me of suspicious levels or activity. Use CloudWatch rules to publish to an SNS topic, with a subscriber to email me.
Client choice: Amplify Client vs Apollo
When working with GraphQL, Amplify lets us choose either the Amplify GraphQL Client or the AppSync SDK, which leverages the much more advanced Apollo client. I’m sticking with the simpler Amplify client for my first venture into GraphQL. Apollo has great support for offline mode and data synchronization. However, my PWA client already takes care of managing offline data and is using S3 for storage, not GraphQL. (GraphQL is only being used to track metadata of shared collections.) I could move all the data to AppSync by modeling it and letting the AppSync resolvers store it into multiple DynamoDB tables. If this were a new application, I probably would. For migrating an existing app though, there isn’t a clear advantage to warrant the additional development time.
Outside of Amplify
The astute reader may notice some capabilities outlined in the requirements aren’t provided by Amplify. That’s unfortunate, but not a barrier. Amplify allows for custom CloudFormation templates, and can also integrate with CloudFormation stacks created by other means. We can even use others tools like Serverless Framework, SAM, and CDK along side Amplify. I haven’t decided yet which approach I will take, but I know it can be done.
Architect It
Now that the business requirements have been listed and considered, the architecture can be built. Much of this is driven by what AWS Amplify does for us, and the discussion above drove the rest:
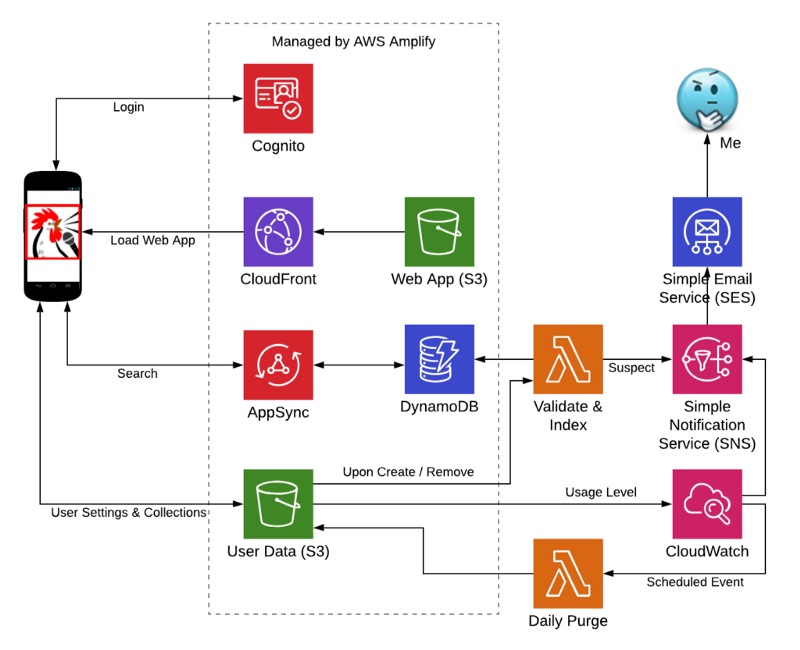
SqAC Cloud Native Architecture with Amplify
Coming next time….
That wraps up the background, requirements, and architecture. Going forward I’ll actually start using Amplify and try to migrate the app. Future posts will document those efforts, whether they lead to successes, wrong turns, or outright failures.




